機械学習を使ってロイヤルティ詐欺を特定することはできるのか

大規模なロイヤルティプラットフォームは、様々な場所から発生する膨大な数のトランザクションを処理し、また同時に多くのメンバーアカウントを管理しています。このような大量のデータ処理を高速で行っているプラットフォームにおいて不正なアクティビティを検出することは、従来の方法では非常に複雑であり、不可能でさえあると言えます。しかし、機械学習(ML)/人工知能(AI)ソリューションを効果的に使用すると、ビジネスクリティカルなロイヤルティシステムの悪用から生じ得る金銭的損失や評判低下による損失を避けるレバレッジ効果が期待できるというのは、プログラム所有者にとっては嬉しい知らせでしょう。
まず、注意しなければいけないのは、このホワイトペーパーで説明する手法がロイヤルティ詐欺を防止する普遍的な解決策ではないということです。ロイヤルティプログラムは、業界、ビジネス目標、コンフィグレーションやその他の要因によりその種類は多様です。さらに、機械学習システムは、費用の見越し額のコンフィグレーション及び償還の制限、登録数の制御、データ検証、リスクが発生しやすいトランザクションの監視、重複排除メカニズムなど、従来行われていた詐欺防止対策を完全に補うことができません。ML /ALソリューションは、既存の不正防止対策をより効果的に行えるように機能しますが、それらの代替となるわけではありません。
ロイヤルティの不正使用とは何か
ロイヤルティの不正使用を一言で定義するのは難しいです。また、様々な自動化メカニズムで使われるアルゴリズムに簡単に変換できるよう短く定義するのも簡単ではありません。一般的に、ロイヤルティの不正使用とは、特定のプログラムの契約内容に違反するある種の技術的又は構成上の抜け穴を利用することを意味します。そして多くの場合、結果的にメンバーが支払う費用又は受け取る報酬が不公平に分配されます。プログラムメンバーの大多数が利用規約に従っていると仮定すると、不正行為は全ての正当なロイヤルティトランザクションに異常がおきた時に特定されます。実際、これはML /AIソリューションの実証済みのユースケースの1つであり、巨大で多様なデータセットの異常を検出します。
一般的に、MLソリューションは、主に監視付きの状態と監視がない状態の二つのカテゴリに分類できます。監視付きのMLソリューションは、不正行為として検出されたトランザクション、アカウント、又はそのほかのアクティビティに関するラベル付きデータを認識するように設定されたシステムです。その結果、MLベースの分類は、特定のデータ機能を選択し、新しいトランザクションと不正ラベル付けされたトランザクションを比較し、それらの類似点を判断して不正を識別し報告します。監視なしの場合は、MLシステムが明示的なラベル付けを認識せず、データ内のパターンと接続を検出します。ラベル付けされた不正インスタンスを含むデータソースを使用するのは非常に効果的ですが、Comarchは特に監視のない手法に焦点を当て、より広範囲な実装に適応できるようにしました。
ロイヤリティプログラムのビジネス目標や目的は様々ですが、最も重要な目標として挙げられるのはリピーターの獲得と維持、ブランド認知度の向上、販売結果の改善です。比較的静的なロイヤルティプログラムのコンフィグレーションを使うと、プログラムとメンバーの間に測定可能な相互作用のパターンを見つけることができます。例を挙げると、
- 獲得と利用率 – メンバーの大半がポイントを引き換える前に通常の発生取引数を決定する。
- 蓄積速度 – ポイントバランスがどれだけ早く伸びるかを学習
- 発生及び償還の典型的な頻度
- 一般的なアカウントの有効期限
- 商品購入とポイント操作の価値
- 登録後の時間とインタラクション総数との関係性についての判断
機械学習システムは、トランザクションデータ内のこれらおよび類似のタイプのパターンを認識し、識別されたモデルと一致しないアカウントまたは個々のトランザクションを検出できます。
ロイヤルティプログラムでの機械学習の使用について
ロイヤルティプログラムの大部分は、顧客が購買した商品の価値に対するロイヤルティポイントを顧客に提供するように構成されています。下の図から分かるように、一般的に支出の合計と獲得ポイントの合計との関係は、ほとんどのプログラムコンフィグレーションにおいて線で表されます。
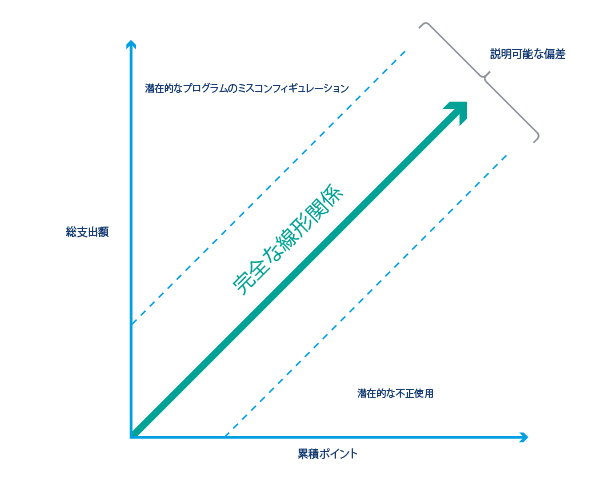 例えば、1ドル払う毎に1ポイントもらえる非常に基本的なロイヤルティプログラムコンフィグレーションを分析すると、メンバーの合計支出と発生したポイントの合計との間の関係は完全な線形で表されるます。しかし現実には、そのようなプログラムは滅多に存在せず、通常、プログラムの所有者は、追加的なキャンペーン、特別オファー、限定商品、ボーナスポイントなどを設定します。したがって、最大値のビジネス知識に基づいて許容範囲ののりしろを考慮しなければなりません。これらのメトリックを絶えず監視し、一部のメンバーのアカウント値が外れているのを発見した場合、以下のことが考えられます。
例えば、1ドル払う毎に1ポイントもらえる非常に基本的なロイヤルティプログラムコンフィグレーションを分析すると、メンバーの合計支出と発生したポイントの合計との間の関係は完全な線形で表されるます。しかし現実には、そのようなプログラムは滅多に存在せず、通常、プログラムの所有者は、追加的なキャンペーン、特別オファー、限定商品、ボーナスポイントなどを設定します。したがって、最大値のビジネス知識に基づいて許容範囲ののりしろを考慮しなければなりません。これらのメトリックを絶えず監視し、一部のメンバーのアカウント値が外れているのを発見した場合、以下のことが考えられます。
- プログラムコンフィグレーションが正しくない – 総支出の多い会員が同様の金額を支払った他の会員よりも獲得ポイントが少ない
- 特定のアカウントで何らかの不正行為が行われた – 合計支出と比較して発生したポイントの合計数が不釣り合いに多い
上記のような場合は調査する必要があります。
Comarch Loyalty ManagementのR&Dチームは、機械学習を使用して異常や不正を検出する方法を詳しく調査しました。
チームは、ML手法の中でも特にオートエンコーダーの使用の分析を行いました。これは入力を圧縮および再構成するように訓練された一種の人口ニュートラルネットワークです。以下の図を参照してください。
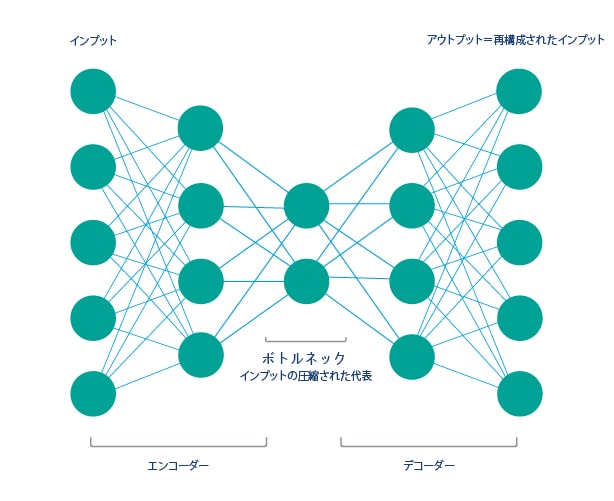
アルゴリズムのパフォーマンスと目的に対する全体的な適性を判断するために、再構築されたアウトプットと元のインプットとが比較されます。オートエンコーダーの再構築が悪いほど、インスタンスが異常である可能性が高くなります。私たちは、会員とプログラムの相互作用とそのポイントのバランスに関する実際のロイヤルティプログラムデータを使用しました。その結果、不自然なポイント取得率、急速なポイントの増減、手動によるポイントの修正、トランザクションの繰り返しなどの異常なパターンを示すアカウントを特定することができました。この方法以外で以上のような異常を検出し特定することは非常に困難です。同チームは分類木とクラスタリングアルゴリズムを使用して、いくつかのテストを実行しましたが、これまでのところ、オートエンコーダーが最も効果的であるという結果が出ています。
つまり、これまでの実験から分かったことは、機械学習ソリューションはロイヤルティプログラム内の不正行為を検出し防止するのに最も確実で優位性があるということです。残存する課題としては、ロイヤルティプラットフォームにそれらを含め、膨大な量のトランザクションをリアルタイムで確実に処理できるようにすることです。包括的な目標は、ロイヤルティエクスペリエンス全体をより安全にすることであり、今後も実現に向けて努めていく所存です。